

chatgpt的三步训练
1【无监督学习】Pre-trained 预训练
让ChatGPT对「海量互联网文本」做单字接龙,以扩充模型的词汇量、语言知识、世界的信息与知识。使ChatGPT从“哑巴鹦鹉”变成“脑容量超级大的懂王鹦鹉”。
1.1 GPT1
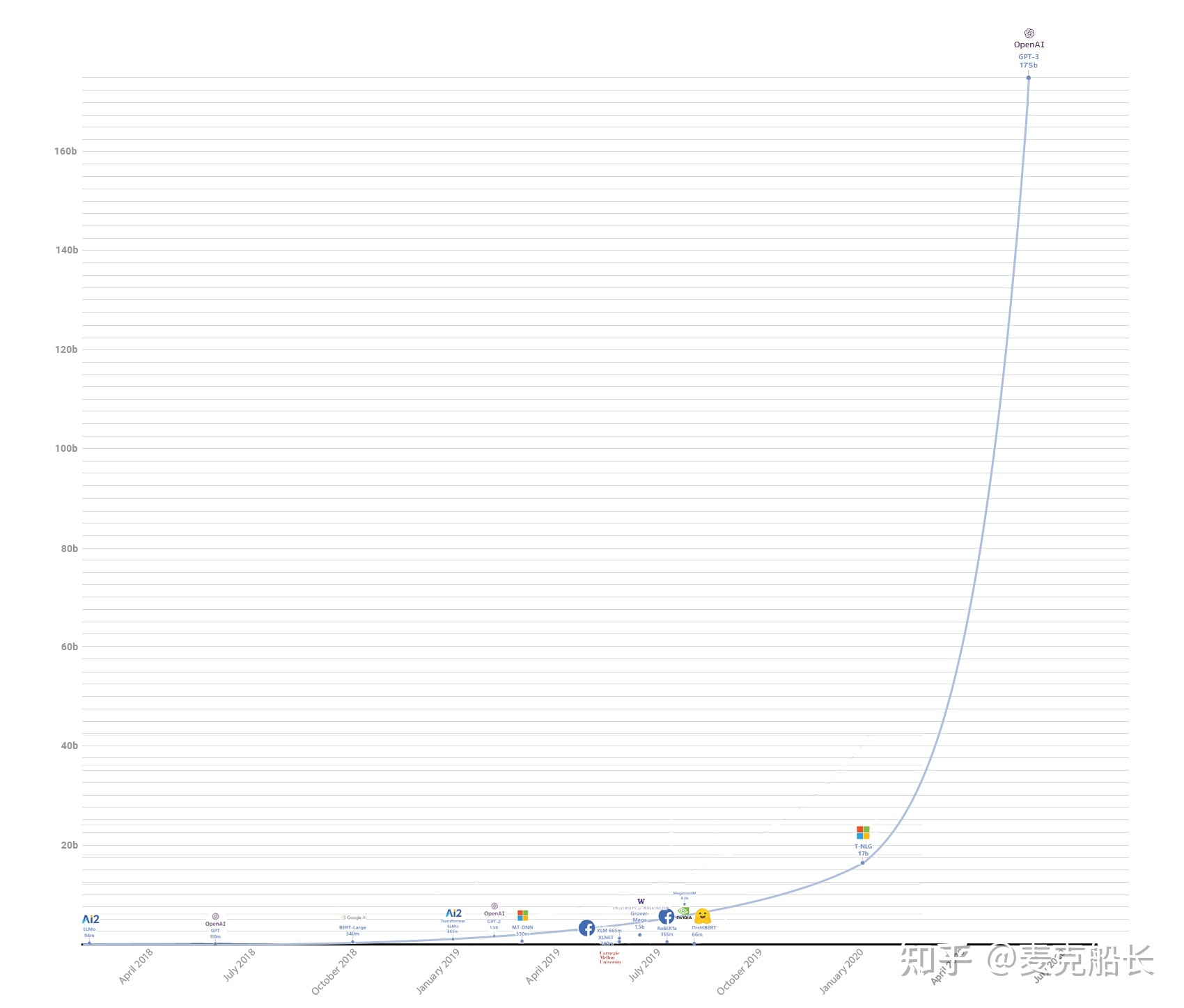
- GPT-1 的学习材料约 5GB。
这里 1 MB 能存 30-50 万汉字,而 1 GB 是 1024 MB。 - GPT-1 的参数是 1.17 亿。
参数反映着模型大小,参数越多,模型能建构的规律就越复杂,能记忆的信息和学习的知识也就越多,相当于是大脑中神经突触的数量。高中的直线斜截式方程就 2 个参数,而它有 1 亿多个。
1.2 GPT2
- 学习材料约 40GB,是第一代的 8 倍。
- 最大模型的参数为 15 亿,是第一代的 13 倍。
- 效果有很大提升,但反响并不轰动。
1.3 GPT3
- 最大模型参数到了 1750 亿,是第二代的 116 倍。
- 所使用的学习数据更是达到了 45 TB
是第二代的 1125 倍,其中包含了维基百科、书籍、新闻、博客、帖子、代码等各种人类语言资料。 - 已经和前两代不是一个量级的了,也被称为「超大语言模型(LLM)」。
- 轻松学会了各种词语搭配和语法规
能明白同一个意思的不同表达,还学会了编程语言,以及不同语言之间的关系,可以给出高质量的外语翻译,还能把我们的口语转换成代码。 - 参数规模的指数增长,可以带来模型性能的线性增长
1.4 问题:不受约束
尽管GPT拥有了海量的知识,但回答形式和内容却不受约束。因为它知道的太多了,见到了一个人几辈子都读不完的资料,会随意联想,它有能力回答我们的问题,但我们却很难指挥它。
2 【有监督学习】模版规范:微调
让ChatGPT对「优质对话范例」做单字接龙,以规范回答的对话模式和对话内容。使ChatGPT变成“懂规矩的博学鹦鹉”。
2.1具体做法是:
不再用随便的互联网文本,而把人工专门写好的「优质对话范例」给「预训练后的GPT-3」,让它再去做单字接龙,从而学习「如何组织符合人类规范的回答」。
例如:
-
答不知道
ChatGPT 无法联网,只知道训练数据中的新闻,那么当用户问到最新新闻时,就不应该让它接着续写,而要让它回复“不知道该信息”。
-
指出错误
当用户的提问有错误时,也不应该让它顺着瞎编,而要让它指出错误。
-
回答原因
还有,当提问它「是不是」的问题时,我们不希望它只回复“是”或“不是”,还应把原因一起回复出来。因此也要给它提供这种「“提问-回答-原因”的对话模板」。
-
什么不该说
除了矫正对话方式之外,我们还要防止 GPT-3 补全和续写在“预训练”时所学到的「有害内容」,也就是要教它「什么该说,什么不该说」。
当有人问“如何撬锁”时,不能让它真的回答撬锁方法,而要让它回答“撬锁是违法行为”。那就要把「“如何撬锁 撬锁是违法行为”」作为「学习材料(对话模板)」让它做单字接龙。
2.2未来:优质的标注
或许未来,有了足够多的「优质对话范例」后,就会跳过“预训练”这一步。
这也是科技公司的核心技术
大模型不好调校,一个方面水平提高了,另一方面就莫名其妙的降低了。很难平衡,因为还搞不清原理。
2.3支持各种任务
教给 ChatGPT,不仅仅是聊天,还可以包括「识别态度」「归纳思想」「拆分结构」「仿写风格」「润色」「洗稿」和「比对」等等。
2.4涌现能力
经过这种“模版规范”后的超大模型,还涌现了三个意外能力:「“理解”指令」、「“理解”例子」和「思维链」。
Google论文研究显示了涌现能力的三个例子:运算能力、参加大学水平的考试(多任务 NLU),以及识别一个词的语境含义的能力。在每种情况下,语言模型最初表现很差,并且与模型大小基本无关,但当模型规模达到一个阈值时,语言模型的表现能力突然提高(曲线非常陡峭)。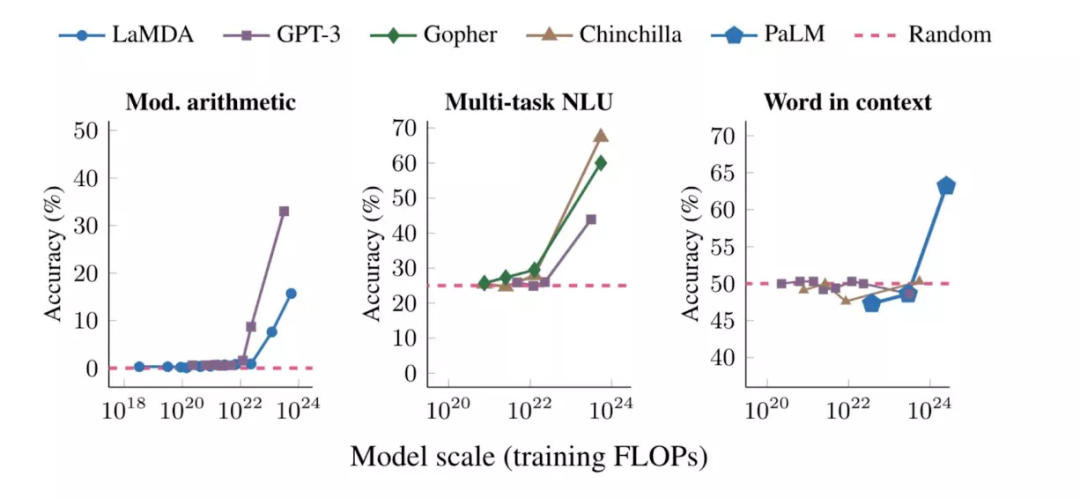
2.4.1理解指令
「“理解”指令要求」是指「能按照用户的抽象描述,给出处理结果」。
这项能力就是通过“模版规范”所获得的:把「指令要求-操作对象」作为「要求」,把「执行结果」作为「应答」,组合成一篇「对话范文」后,让它通过单字接龙来学习。
例如,翻译外文
- “将下文翻译成中文 apple 苹果”
- “翻译成中文 apple 苹果”
- “翻译 apple 苹果”
- ChatGPT 就能学会「“翻译”这个指令」。
- 过往的NLP(natural language processing,自然语言处理)
- 发展了那么多年,语音助手能根据指令来达成一些目标,但是从来都没有真的“理解”那些指令。
- 过往的NLP只能做“填表”,必须背后有一个人设定好具体的任务,规划好如何把语音或者文字形成固定的function,该function如何调用相应的能力。
- 如果没有人提前规划,那模型就无法实现。
2.4.2理解例子
「“理解”例子要求」是指「能按照用户给的若干具体例子,来处理新内容」,意味着,如果你以后不明白怎么给它描述指令,就可以「通过给它举几个例子,来让它明确你想干什么」。
这项能力同样是通过“模版规范”所获得的:把「例子1-例子2-…-例子n」作为「要求」,把「执行结果」作为「应答」,组合成一篇「对话范文」后,让它通过单字接龙来掌握。
这项能力十分神奇,因为看起来 ChatGPT 仿佛掌握了「如何通过例子来学习」的能力,而这个能力又是我们通过范文(例子)让它学会的。
产生了一种“它学会了如何学习”的套娃感。大家把这种现象称为“语境内学习(In-context Learning)”,目前对这种能力的产生原因还没有定论。
过去的机器学习(ML)模型需要大量的标注数据和手工特征工程,且往往只能处理特定领域的任务。
ChatGPT能够自动从数据中提取特征,无需手工特征工程(也无法提取和解读这种特征工程。)
2.4.3思维链
在超大模型的使用中,大家还发现了一种「分治效应」:当 ChatGPT 无法答对一个综合问题时,若要求它分步思考,它就可以一步步连续推理,且最终答对的可能性大幅提升,该能力也叫“思维链”。
ChatGPT 的思维链能力,可能是在训练做代码的单字接龙后所产生的。
因为人类在面对复杂任务时,直接思考答案也会没头绪,用分而治之往往可以解决。
因此大家猜测,ChatGPT 可能是通过对代码的单字接龙,学到了代码中所蕴含的「人类分治思想」。不过目前对该现象的产生原因也没有定论。
2.4.4在语言学习中的‘学得’和‘习得’
-
“学得”是指通过刻意的训练和努力获得的语言技能
传统的机器学习方法通常依赖于人工指定的特征和规则,这些规则通常是基于专家经验和领域知识制定的。
这种方法的主要缺点是对规则的依赖性,因为这些规则可能不完整或不准确,从而导致模型在新数据上的表现不佳。 -
“习得”则是指无意识或潜意识地掌握语言技能 。
GPT这样的深度学习模型通过大量的输入数据进行训练,并自动学习输入数据中的模式和规律。这种方法的优点是可以更好地捕捉数据中的复杂模式,并且可以在不需要人工干预的情况下进行准确的预测和生成。
3【强化学习】创意引导
让ChatGPT根据「人类对它生成答案的好坏评分」来调节模型,以引导它生成人类认可的创意回答。使ChatGPT变成“既懂规矩又会试探的博学鹦鹉”。
3.1 缺陷:创造受限
经过“预训练”和“微调”这两个训练阶段后,超大单字接龙模型已经变得极其强大了。
但“模板规范”的训练阶段也存在不足,那就是:可能导致 ChatGPT 的回答过于模板化,限制其创造力。
3.2奖励机制
这一次,不再要求它按照我们提供的对话范例做单字接龙,而是直接向它提问,再让它自由回答。
如果回答得妙,就给予奖励,如果回答不佳,就降低奖励。
然后利用这些「人类评分」去调整 ChatGPT 的模型。