
现在的LLM和Chatbot这么多,俗话说的好文无第一、武无第二,他们到底谁更厉害呢?今天看到一个非常有意思的东西 Chatbot Arena,就是要解决这个问题的。这是一个大型语言模型 (LLM) 的基准平台,以众包方式进行匿…
来源: 问世间、谁是SOTA,Chatbot Arena,大语言模型(LLM)的角斗场来了,各种LLM一起来华山论剑吧 – 知乎
问世间、谁是SOTA,Chatbot Arena,大语言模型(LLM)的角斗场来了,各种LLM一起来华山论剑吧

现在的LLM和Chatbot这么多,俗话说的好文无第一、武无第二,他们到底谁更厉害呢?今天看到一个非常有意思的东西Chatbot Arena,就是要解决这个问题的。
这是一个大型语言模型 (LLM) 的基准平台,以众包方式进行匿名、随机的战斗。在5月初,研究团队发布了他们的初步结果和基于 Elo 评级系统的排行榜,Elo是国际象棋和其他竞技游戏中广泛使用的评级系统。
资源参考与链接:
演示: https: //arena.lmsys.org
排行榜: https: //leaderboard.lmsys.org
GitHub: https://github.com/lm-sys/FastChat
Colab 笔记本:https://colab.research.google.com/drive/1lAQ9cKVERXI1rEYq7hTKNaCQ5Q8TzrI5 ?usp=sharing
BLOG:Blog | LMSYS Org
方法介绍:
随着 ChatGPT 的巨大成功,经过微调以遵循指令的开源大型语言模型激增。这些模型能够针对用户的问题/提示提供有价值的帮助。著名的例子包括基于 LLaMA 的 Alpaca 和 Vicuna,以及基于 Pythia 的 OpenAssistant 和 Dolly。
尽管每周都会不断发布新模型,但社区在有效地对这些模型进行基准测试方面面临着挑战。对 LLM 助手进行基准测试极具挑战性,因为问题可以是开放式的,而且很难编写一个程序来自动评估响应质量。在这种情况下,研究团队通常不得不求助于基于成对比较的人工评估。这是一些比较时的期望属性。
- 可扩展性。当无法收集足够的数据来评估所有可能的模型对时,系统应该能够扩展到大量的模型。
- 增量性。系统应该能够使用相对较少的试验来评估一个新模型。
- 唯一排序。系统应该为所有模型提供唯一的排序。对于任意两个模型,我们应该能够确定哪个排名更高或它们是否并列。
现有的LLM基准系统(LLM benchmark systems)很少同时满足这些属性。传统的LLM基准框架,如HELM和lm-evaluation-harness,为学术研究中常用的任务提供多指标测量。然而,它们不是基于成对比较,并且在评估开放式问题方面不够有效。OpenAI还推出了evals项目来收集更好的问题,但该项目并未为所有参与模型提供排名机制。当发布Vicuna模型时,研究团队采用了基于GPT-4的评估流程,但它并没有提供可扩展和增量评级的解决方案。
于是研究团队研发了Chatbot Arena,这是一个以众包方式进行匿名随机对战的LLM基准平台。Chatbot Arena采用了Elo评分系统,这是国际象棋和其他竞技游戏中广泛使用的评分系统。Elo评分系统有望提供上述所述的期望属性。而且Anthropic LLM论文也采用了Elo评分系统。

随着 ChatGPT 的巨大成功,经过微调以遵循指令的开源大型语言模型激增。这些模型能够针对用户的问题/提示提供有价值的帮助。著名的例子包括基于 LLaMA 的 Alpaca 和 Vicuna,以及基于 Pythia 的 OpenAssistant 和 Dolly。
尽管每周都会不断发布新模型,但社区在有效地对这些模型进行基准测试方面面临着挑战。对 LLM 助手进行基准测试极具挑战性,因为问题可以是开放式的,而且很难编写一个程序来自动评估响应质量。在这种情况下,我们通常不得不求助于基于成对比较的人工评估。
基于成对比较的良好基准系统有一些所需的属性。
- 可扩展性。当无法为所有可能的模型对收集足够的数据时,系统应扩展到大量模型。
- 增量性。该系统应该能够使用相对较少的试验来评估新模型。
- 独特的秩序。系统应该为所有模型提供唯一的顺序。给定任何两个模型,我们应该能够分辨出哪个排名更高或者它们是否并列。
现有的 LLM 基准系统很少满足所有这些属性。经典的 LLM 基准框架,例如HELM和lm-evaluation-harness,为学术研究中常用的任务提供多指标测量。然而,它们不是基于成对比较,并且不能有效地评估开放式问题。OpenAI 也推出了evals项目来收集更好的问题,但这个项目并不提供所有参与模型的排名机制。当我们推出Vicuna模型时,我们使用了基于 GPT-4 的评估管道,但它没有提供可扩展和增量评级的解决方案。
在这篇博文中,我们介绍了 Chatbot Arena,这是一个以众包方式提供匿名随机战斗的 LLM 基准平台。Chatbot Arena 采用Elo 评分系统,这是一种在国际象棋和其他竞技游戏中广泛使用的评分系统。Elo 评级系统有望提供上述所需的属性。我们注意到Anthropic LLM 论文也采用了 Elo 评分系统。
为了收集数据,我们在一周前推出了几个流行的开源 LLM 的竞技场。在竞技场中,用户可以与两个匿名模特并排聊天,并投票选出哪个更好。这种众包数据收集方式代表了 LLM 在野外的一些用例。几种评价方法的比较如表2所示。
表 2:不同评估方法之间的比较。
| HELM / lm-评估-线束 | 开放人工智能/评估 | 羊驼评估 | 骆驼评价 | 聊天机器人竞技场 | |
|---|---|---|---|---|---|
| 题源 | 学术数据集 | 混合的 | 自指导评估集 | GPT-4 生成 | 用户提示 |
| 评估员 | 程序 | 程序/模型 | 人类 | GPT-4 | 用户 |
| 指标 | 基本指标 | 基本指标 | 赢率 | 赢率 | Elo 评级 |
数据采集
研究团队使用他们的多模型服务系统FastChat在https://arena.lmsys.org托管了竞技场。当用户进入竞技场时,他们可以与两个匿名模型并排聊天,如图 1 所示。
战斗画面:

在得到两个模型的响应后,用户可以继续聊天或投票给他们认为更好的模型。提交投票后,将显示模型名称。用户可以与两个随机选择的新匿名模型继续聊天或重新开始新的战斗。该平台记录所有用户交互。在我们的分析中,我们仅在隐藏模型名称时使用投票。
Elo评级系统
Elo评分系统是一种计算玩家相对技能水平的方法,已广泛应用于竞技游戏和体育运动中。两名球员之间的评分差异可以预测比赛的结果。Elo 评级系统对我们的案例很有效,因为我们有多个模型,并且我们在它们之间进行成对的战斗。
如果玩家 A 的评分为Ra,玩家 B 的评分为Rb,则玩家 A 获胜概率的确切公式(使用以 10 为底的逻辑曲线)为
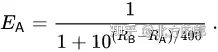
玩家的评分可以在每场战斗后线性更新。假设玩家 A(具有 Rating Ra)被期望得分Ea但实际得分Sa。更新玩家评分的公式是
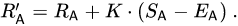
使用收集到的数据,我们计算了该笔记本中模型的 Elo 评分,并将主要结果放在表 1 中。欢迎您试用笔记本并自己玩弄投票数据。数据只包含投票结果,没有对话历史,因为公开对话历史会引起隐私和毒性等担忧。
双赢率
作为校准的基础,这是5月3日时锦标赛中每个模型的成对获胜率(图 4)以及使用 Elo 评级估算的预测成对获胜率(图 5)。通过比较数据,我们发现 Elo 评级可以相对较好地预测胜率。


5月3日报告主要内容:
报告:Chatbot Arena: Benchmarking LLMs in the Wild with Elo Ratings | LMSYS Org
对比的模型主要是开源模型:
表 1. 流行的开源大型语言模型的 Elo 评级。(时间范围:2023年4月24日-5月1日)

此时研究团队已经收集了 4.7k 的有效匿名投票。这是一些简短总结:

图 2 显示了每个模型组合的战斗计数。当我们最初发起比赛时,我们根据我们的基准获得了关于可能排名的先验信息,并选择根据这个排名来配对模型。根据这个排名,我们优先考虑我们认为会是强配对的东西。然而,我们后来改用统一抽样以获得更好的排名整体覆盖率。在比赛接近尾声时,我们还推出了一种新模型fastchat-t5-3b。所有这些都会导致模型频率不均匀。

图 3 描绘了语言分布,并显示大多数用户提示都是英语。
5月10日报告主要内容:
报告地址:Chatbot Arena Leaderboard Updates (Week 2) | LMSYS Org
加入了GPT-4,Claude等大模型,结果就是GPT-4毫无疑问的登顶了。

不顾仔细观察可以发现以下一些有意思的东西:
- Claude超过了GPT3.5,与GPT-4的成绩差的也不大,这说明了Google的追赶速度。
- 中文的ChatGLM-6B的成绩也不错,尤其考虑到这个比赛用的最多的是英语。
这是一些细节:
GPT-4 什么时候失效?
这是一些用户不喜欢 GPT-4 的例子。

在图 中,用户提出了一个需要仔细推理和规划的棘手问题。尽管 Claude 和 GPT-4 都提供了相似的答案,但由于针位于顶部,Claude 的反应稍微好一些。然而,研究团队观察到由于抽样的随机性,这个例子的结果不能总是被复制。

在图 2 中,尽管 Claude 和 GPT-4 具有惊人的能力,但它们仍需要继续努力来解决这种棘手的推理问题。
除了这些棘手的案例,还有很多不需要复杂推理或知识的简单问题。在这种情况下,像 Vicuna 这样的开源模型的性能可以与 GPT-4 相媲美,因此我们可以使用稍微弱一点(但更小或更便宜)的 LLM 来代替更强大的 GPT-4。
获胜分数矩阵

特定语言排行榜
最后,研究团队通过将对话数据根据语言分为两个子集,展示了两个特定语言排行榜:(1) 纯英语和 (2) 非英语。我们可以看出 Koala 在非英语语言方面更差,而 ChatGLM-6B 在非英语语言方面更好。这是因为他们的训练数据的组成不同。

加油ChatGLM!!!!
让我们去战一下吧:
战场:https://chat.lmsys.org/?leaderboard
进入页面后可以看到有4个分页:

Single Model
其中Single Model是每个模型的测试场地:


Chatbot Arena (battle):
Chatbot Arena (battle)是真正的战场,这里面是看不到模型名字的:

很明显,对于这个比试,模型A完胜。
Chatbot Arena (side by side):
这个是能看到模型名字的,按照介绍,这个的结果应该是不计入到排行榜的

Leaderboard
Leaderboard就是排行榜:



感觉有帮助的朋友,欢迎赞同、关注、分享三连。^-^