
阿里云Qwen团队隆重推出Qwen3嵌入式表征模型家族,这一系列全新模型基于Qwen3核心架构开发,专门服务于文本编码、信息检索以及内容排序等关键应用场景。凭借Qwen3在多语言理解领域的深厚积累,这些模型在各类基准测试中均展现出领先的性能表现。我们采用Apache 2.0开源许可将模型权重和配套代码公开在多个主流平台,同时发布了详细的技术手册与实现方案。

排序模型性能对比
| 模型名称 | 参数量 | 国际测试 | 中文测试 | 多语言测试 | 长文本检索 | 代码检索 | 专项评估 |
|---|---|---|---|---|---|---|---|
| Qwen3-Embedding-0.6B | 0.6B | 61.82 | 71.02 | 64.64 | 50.26 | 75.41 | 5.09 |
| 竞品模型A | 0.3B | 58.22 | 63.37 | 63.73 | 39.66 | 58.98 | -0.68 |
| 竞品模型B | 0.3B | 59.51 | 74.08 | 59.44 | 66.33 | 54.18 | -1.64 |
| 竞品模型C | 0.6B | 57.03 | 72.16 | 58.36 | 59.51 | 41.38 | -0.01 |
| Qwen3-Reranker-0.6B | 0.6B | 65.80 | 71.31 | 66.36 | 67.28 | 73.42 | 5.41 |
| Qwen3-Reranker-4B | 4B | 69.76 | 75.94 | 72.74 | 69.97 | 81.20 | 14.84 |
| Qwen3-Reranker-8B | 8B | 69.02 | 77.45 | 72.94 | 70.19 | 81.22 | 8.05 |
技术说明 :
- 评测数据来自MTEB(英文v2)、MTEB(中文v1)、MTEB(多语言)以及MTEB(代码)检索子集,分别记为MTEB-R、CMTEB-R、MMTEB-R和MTEB-Code。
- 排序测试基于Qwen3-Embedding-0.6B召回的前100个候选结果。
核心优势 :
卓越的适应能力 : Qwen3表征模型在多项标准评估中获得顶尖成绩。其中8B版本在全球多语言榜单中荣登榜首(2025年6月5日统计,得分70.58),大幅超越同类商业解决方案。排序模块的引入显著提升了检索结果的相关度排序质量。
可配置的模型架构 : 系列产品提供0.6B至8B多种规模选项,支持实际应用中的性能优化。开发者可以自由搭配使用表征模块与排序模块拓展功能边界。模型支持两大特色功能:1) 表征维度可调:用户可依需求调整输出维度,优化存储效率;2) 指令模板定制:通过任务特定的提示模板增强目标场景效果。
广泛的语言覆盖 : 支持100余种自然语言和编程语言的文本处理,在多语言混合环境和代码检索等复杂场景下表现优异。
产品规格
| 模型类别 | 具体型号 | 参数量 | 网络层数 | 最大长度 | 表征维度 | 维度调节 | 指令支持 |
|---|---|---|---|---|---|---|---|
| 文本编码 | Qwen3-Embedding-0.6B | 0.6B | 28 | 32K | 1024 | 支持 | 支持 |
| Qwen3-Embedding-4B | 4B | 36 | 32K | 2560 | 支持 | 支持 | |
| Qwen3-Embedding-8B | 8B | 36 | 32K | 4096 | 支持 | 支持 | |
| 文本排序 | Qwen3-Reranker-0.6B | 0.6B | 28 | 32K | – | – | 支持 |
| Qwen3-Reranker-4B | 4B | 36 | 32K | – | – | 支持 | |
| Qwen3-Reranker-8B | 8B | 36 | 32K | – | – | 支持 |
注:维度调节指标明编码模型是否支持输出维度调整;指令支持指标明模型是否能够根据特定任务指令优化表现。
技术实现
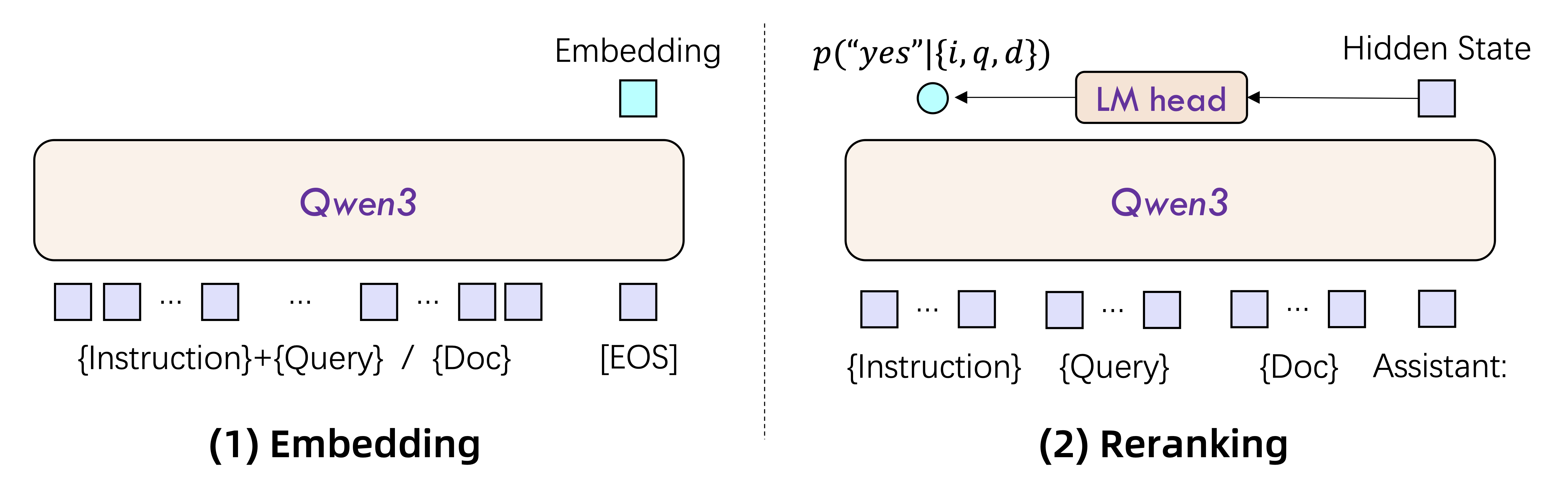
Qwen3系列模型在底层架构上采用两种设计模式:编码模型采用双塔结构处理单文本输入,排序模型采用单塔结构评估文本相关性。通过LoRA微调技术,我们充分保留了基础模型的语义理解能力。具体而言:1) 编码模型取最终层[EOS]标记的隐含状态作为文本表示;2) 排序模型直接计算文本对的匹配分数。
训练方案
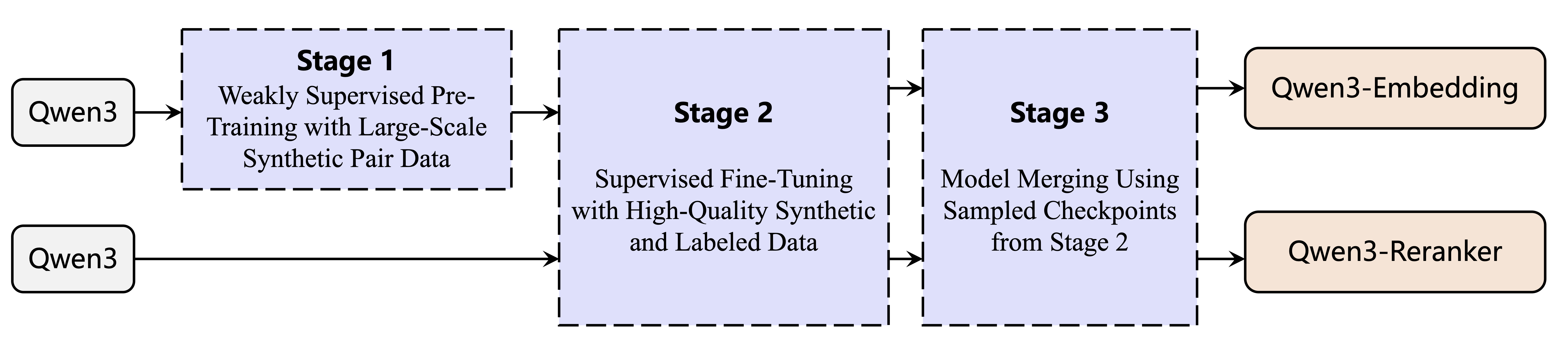
Qwen3系列延续并改进了GTE-Qwen的训练策略,针对性地优化了各模块训练流程。编码模型采用三个阶段渐进式训练:首先是基于海量弱监督数据的对比学习,其次是标注数据精调,最后进行模型集成以提升整体表现。排序模型则直接使用高质量标注数据训练以提升效率。
在弱监督数据构建环节,我们创新性地利用Qwen3生成能力批量创建适配各类任务的文本组合,突破了传统方法依赖公开资源的限制,大幅提升了数据生产效率。
未来展望
我们将持续优化Qwen3系列模型的推理效率,提升实际部署表现。同时计划扩展多模态理解能力,构建跨领域的语义表示体系。期待开发者社区共同探索更多创新应用场景。