

机器学习算法之K-近邻(KNN)
什么是K-近邻算法?
K近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。
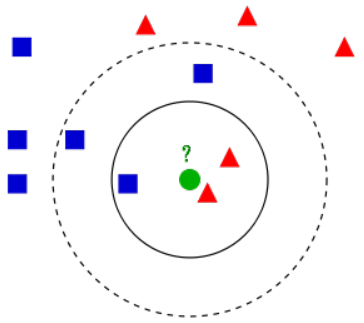
k近邻算法例子。测试样本(绿色圆形)应归入要么是第一类的蓝色方形或是第二类的红色三角形。如果k=3(实线圆圈)它被分配给第二类,因为有2个三角形和只有1个正方形在内侧圆圈之内。如果k=5(虚线圆圈)它被分配到第一类(3个正方形与2个三角形在外侧圆圈之内)。
如上所述,这里K值的大小可以任意设定(当K=1时,称算法为最近邻算法),但是k值的选择会对KNN的结果产生重大影响,因此K值的选择具有极其重要的意义。
- 当选择的K值较小时,用于预测的训练数据集则较小,此时近似误差会减小,但是其估计误差会增大,预测结果对近邻的实例点非常敏感。若此时近邻的实例点是噪声,预测就会出错。
- 当选择的K值较大时,用于预测的训练数据集则较大,此时估计误差会减小,但是其近似误差又会增大,此时与输入实例较远(不相似)的实例也会对预测起作用,使预测发生错误。
在实际的应用中,通常会选择较小的K值。由于K值小时意味着整体的模型变得复杂,容易形成过拟合,因此通常采用交叉验证的方式选择最优的K值。
KNN算法的优缺点
- 优点:精度高、对异常值不敏感、无数据输入假定
- 缺点:计算复杂度高、空间复杂度高(在高维情况下,会遇到『维数灾难』的问题)
KNN算法三要素
KNN算法我们主要考虑三个重要的要素,对于固定的训练集,只要这三点确定了,算法的预测方式也就决定了。这三个最终的要素距离度量、 k值的选择和分类决策规则决定。
距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反映。k近邻模型的特征空间一般是n维实数向量空间 ,使用的距离是一般是欧式距离,也可以是其他距离。由不同的距离度量所确定的最近邻点是不同的。
K值的选择
k值的大小决定了邻域的大小。较小的k值使得预测结果对近邻的点非常敏感,如果近邻的点恰好是噪声,则预测便会出错。话句话说,k值的减小意味着整体模型变得复杂,容易发生过拟合。较大的k值会让输入实例中较远的(不相似的)训练实例对预测起作用,使预测发生错误,k值的增大意味着整体模型变得简单。在实际的应用中,一般采用一个比较小的K值。并采用交叉验证的方法,选取一个最优的K值。一个极端是k等于样本数m,则完全没有分类,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
分类决策规则决定
k近邻法中的分类规则往往是多数表决,即由输入实例的k个近邻的训练实例中的多数类决定输入的实例。但这个规则存在一个潜在的问题:有可能多个类别的投票数同为最高。这个时候,可以通过以下几个途径解决该问题:
- 从投票数相同的最高类别中随机地选择一个;
- 通过距离来进一步给票数加权;
- 减少K的个数,直到找到一个唯一的最高票数标签。
近邻算法中的分类决策多采用多数表决的方法进行。它等价于寻求经验风险最小化。
K-近邻算法的实现
线性扫描
KNN的最简单朴素的方法即直接线性扫描,大致步骤如下:
- 计算待预测数据与各训练样本之间的距离
- 按照距离递增排序
- 选择距离最小的k个点
- 计算这k个点类别的频率,最高的即为待预测数据的类别。
from collections import defaultdict
def __init__(self, k=2):
def distance(p1, p2):
return math.sqrt(x_ 2 + y_ 2)
self.data = dict(zip(X, y))
def predict(self, point):
for p, _ in self.data.items():
distances[p] = self.distance(p, point)
sort_distances = dict(sorted(distances.items(), key=lambda x: x[1]))
topk = defaultdict(int)
for idx, (p, v) in enumerate(sort_distances.items()):
if idx == self.k - 1:
topk[self.data[p]] += 1
topk = sorted(topk.items(), key=lambda x: -x[1])
return topk[0][0]
if __name__ == '__main__':
points = [(1, 1), (1, 1.2), (0, 0), (0, 0.2), (3, 0.5), (3.3, 0.9)]
labels = ['A', 'A', 'B', 'B', 'C', 'C']
knn.fit(points, labels)
label = knn.predict((0.9, 0.7))KD树
线性扫描非常耗时,为了提高k近邻搜索的效率,可以考虑使用特殊的结构存储训练数据,以减少计算距离的次数。kd树是一种对k维空间的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树,表示对k维空间的一个划分(partition),构造kd树相当于不断用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树中的每个节点对应一个k维超矩形区域。
KD树(k-dimensional tree),也可称之为K维树,可以用更高的效率来对空间进行划分,并且其结构非常适合寻找最近邻居和碰撞检测。对于2维空间,KD树可称为2D树,因为空间只有两个坐标轴;对于3维空间,KD树可称为3D树,空间中有三个坐标轴;以此类推。
对于不同维度的空间,KD树的构建思路完全一致。下面以二维空间为例。KD树的本质是一个二叉树,即一个根节点,划分为左子树和右子树。所以KD树的构建无非是两个问题:根节点的选择,左右子树的划分规则。
以下是KD树的构建过程。
- 选定一个轴,比如X轴,选择这个轴上的中位数的所在点为根节点
- 所有X比中位数X小的,都划分为左子树;反之,则划分为右子树
- 对于左右两个子树,重复第一步,但是需要把划分轴换成另外一个轴(Y)继续
- 重复以上过程,直到所有点都加入KD树中
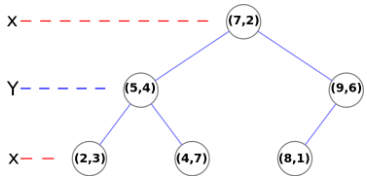
以上图举例,第一步对X轴进行划分,点(7,2)的X坐标7为所有X坐标的中位数,其被确立为根节点;X坐标比7小的点(5,4)、(2,3)、(4,7)被划分到左子树;X坐标比7大的点(9,6)、(8,1)被划分到右子树。对于左子树(5,4)、(2,3)、(4,7),对它们的Y轴进行划分,点(5,4)的Y坐标4为所有左子树的Y坐标的中位数,其被确立为左子树的根节点;Y坐标比4小的点(2,3)被划分为左子树;Y坐标比4大的点(4,7)被划分为右子树。对于右子树(9,6)、(8,1),和左子树同理,也是对Y轴进行划分。此时所有点都已经加入到KD树中,创建结束。
一个直观的理解是,创建方式看起来有点像对空间横纵切蛋糕的方式,对于2D空间,第一刀沿着X轴将空间划分为两半,第二刀又沿着Y轴分别将已经划分好的两半再划分为两半,第三刀又继续沿着X轴进行划分……直到所有点都落入KD树中。对于3D空间,则是沿着X->Y->Z->X此类的循环依次对空间进行对半分割。(决定在哪个维度上进行分割是由所有数据在各个维度的方差决定的,方差越大说明该维度上的数据波动越大,更应该再该维度上对点进行划分。例如x维度方差较大,所以以x维度方向划分。)
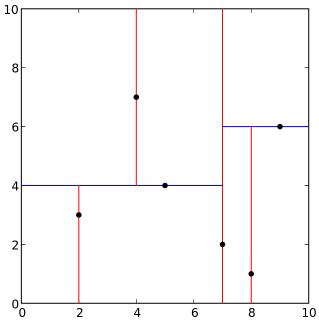
构建完一颗KD-TREE之后,如何使用它来做KNN检索呢?用下面的20s的GIF动画来表示:
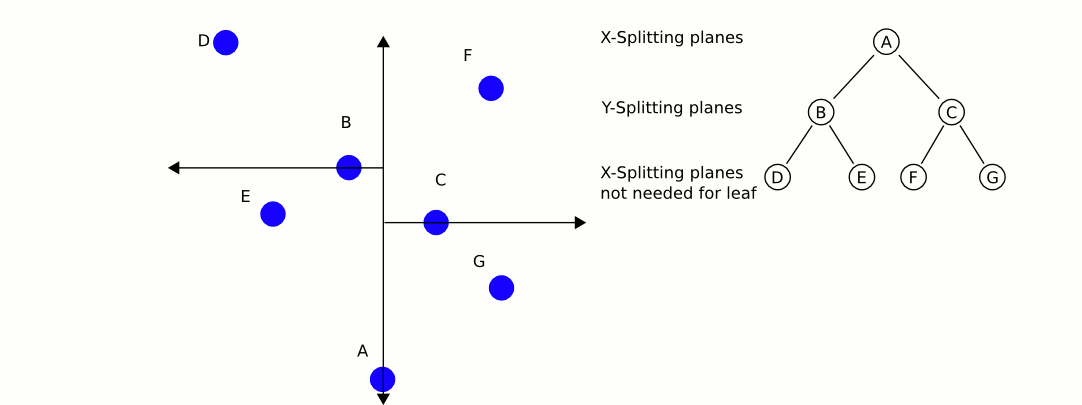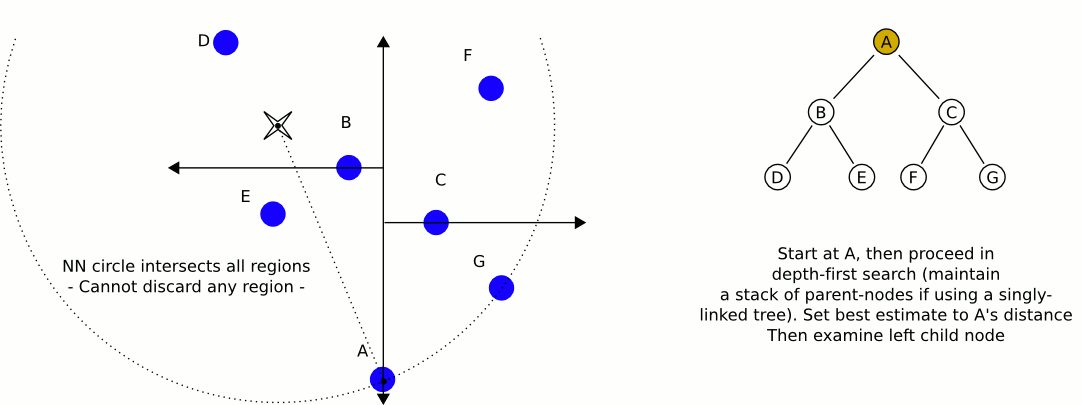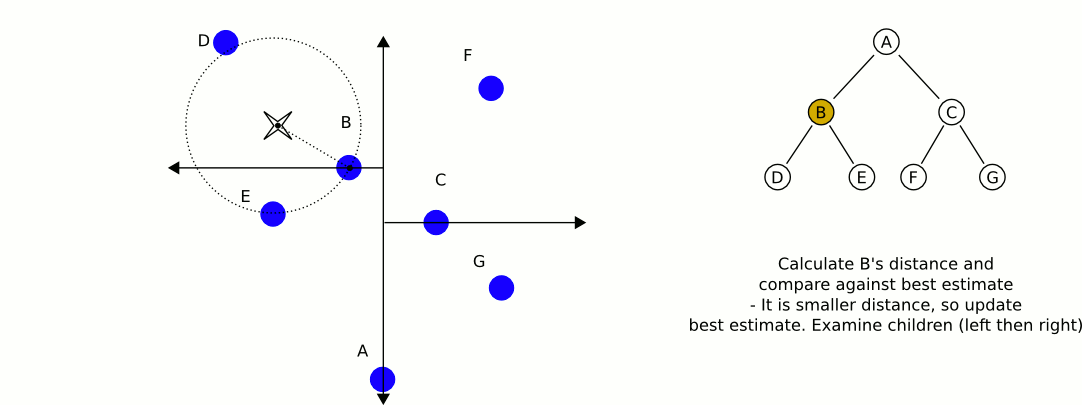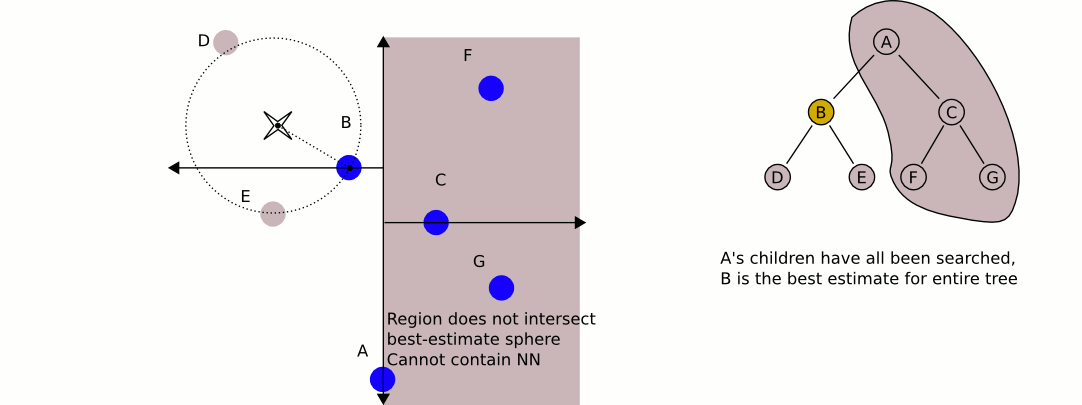
以下是寻找最近邻居算法的描述:
- 建立一个空的栈S
- 对于给定的查询点P,沿着根节点遍历整个KD树,直到不能再遍历为止,将每个遍历的点都入栈(Push)
- 遍历的过程非常简单,对于KD树中的点和这个点的划分坐标,如果查询点比这个点的划分坐标大,则继续遍历这个点的右子树,否则遍历这个点的左子树
- 若栈非空,开始循环,设最邻近距离为无穷大
- 将栈顶的点P弹出(Pop),计算查询点与之的距离Dist,如果Dist小于最邻近距离,则更新最近邻距离为Dist,同时更新最邻近点为P
- 判断点P的划分轴,若查询点到划分轴的距离小于最近邻距离,则说明在划分轴的另外一侧还可能存在更邻近的点,需要在划分轴的另一侧的根节点再执行一次遍历,将每个遍历的点都入栈(Push)
- 若栈为空,则终止循环,返回结果
以上算法用到了栈来模拟递归,避免了递归的函数深层调用和返回的开销。
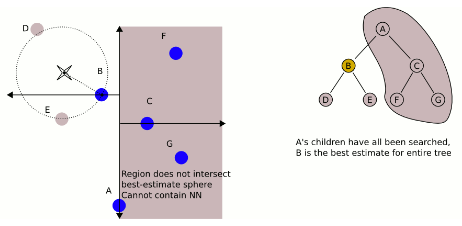
KD树之所以如此高效的原因在于第六步,也就是剪枝。如上图所示,在已经搜索到B时,发现其到B的距离,要比到A的右子树的平面距离还更短,所以整个A的右子树都被剪枝,一下子剪去了一半的点。
from collections import defaultdict
def __init__(self, topk=3):
def build_kdtree(self, points, depth=0):
if n <= 0: # 如果当前子空间已经没有点了则构建过程结束
axis = depth % 2 # 计算当前选择的坐标轴
sorted_points = sorted(points, key=lambda point: point[axis]) # 对当前子空间的点根据当前选择轴的值进行排序
median = n // 2 # 中位数取排序后坐标点的中间位置的数
'point': sorted_points[median], # 当前根结点
'left': self.build_kdtree(sorted_points[:median], depth + 1), # 将超平面左边的点交由左子结点递归操作
'right': self.build_kdtree(sorted_points[median + 1:], depth + 1) # 同理,将超平面右边的点交由右子结点递归操作
def distance(p1, p2):
if p1 is None or p2 is None:
return math.sqrt(x_ 2 + y_ 2)
def closer_distance(self, point, p1, p2):
d1 = self.distance(point, p1)
d2 = self.distance(point, p2)
return (p2, d2)
return (p1, d1)
return (p1, d1) if d1 < d2 else (p2, d2)
def kdtree_closest_point(self, root, point, depth=0):
next_branch = None
opposite_branch = None
# 以下主要是比较当前点到根结点和两个子结点之间的距离
if point[axis] < root['point'][axis]:
next_branch = root['left']
opposite_branch = root['right']
next_branch = root['right']
opposite_branch = root['left']
best, closer_dist = self.closer_distance(
self.kdtree_closest_point(
next_branch,
depth + 1),
root['point']
if self.distance(point, best) > abs(point[axis] - root['point'][axis]):
best, closer_dist = self.closer_distance(
self.kdtree_closest_point(
opposite_branch,
point,
depth + 1),
if best in self.store and self.store[best] > closer_dist:
self.store[best] = closer_dist
self.store[best] = closer_dist
self.data = dict(zip(X, y))
self.kdtree = self.build_kdtree(X)
def predict(self, point):
best = self.kdtree_closest_point(self.kdtree, point)
sorted_stores = sorted(self.store.items(), key=lambda x: x[1])[:self.topk]
counter = defaultdict(int)
for candidates, score in sorted_stores:
counter[self.data[candidates]] += 1
sorted_counter = sorted(counter.items(), key=lambda x: -x[1])
counter = list(counter.items())
if len(counter) > 1:
if counter[0][1] != counter[1][1]:
best = counter[0][1]
return self.data[best]
if __name__ == '__main__':
points = [(1, 1), (1, 1.2), (0, 0), (0, 0.2), (3, 0.5), (3.3, 0.9)]
labels = ['A', 'A', 'B', 'B', 'C', 'C']
knn.fit(points, labels)
label = knn.predict((0.9, 0.9))使用Scikit-Learn进行分类预测
由于Scikit-Learn包中已经封装好了KNN方法,所以使用起来非常的简单。具体代码如下:
weather = ['Sunny','Sunny','Overcast','Rainy','Rainy','Rainy','Overcast','Sunny','Sunny',
'Rainy','Sunny','Overcast','Overcast','Rainy']
temperature = ['Hot','Hot','Hot','Mild','Cool','Cool','Cool','Mild','Cool','Mild','Mild','Mild','Hot','Mild']
play=['No','No','Yes','Yes','Yes','No','Yes','No','Yes','Yes','Yes','Yes','Yes','No']
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
weather_encoded=le.fit_transform(weather)
temperature_encoded=le.fit_transform(temperature)
features=list(zip(weather_encoded,temperature_encoded))
label=le.fit_transform(play)
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(features,label)
predicted= model.predict([[0,2]]) # 0:Overcast, 2:Mild使用Grid Search确定K值
使用KNN遇到的最大问题和使用K-Means类似,就是怎么确定K值,常见的方法主要是Grid Search。简单的说就是遍历K值,然后再计算评分,去评分最好的值作为最终选择。
这里我们使用Scikit-Learn自带的葡萄酒数据集,该数据是对意大利同一地区种植的三种不同品种葡萄酒进行化学分析的结果。这项分析确定了三种葡萄酒中每种葡萄酒中13种成分的含量。该数据库包括13个特征和一个目标(品种类型)。品种类型包括:’0类’、’1类’和’2类’。
from sklearn import datasets
wine = datasets.load_wine()
print(wine.feature_names) #获取特性向量名称
print(wine.target_names) #获取分类标签名称
print(wine.data[0:5]) #查看特征向量数据
print(wine.target) #查看分类标签数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3)# 70% training and 30% test
from sklearn.neighbors import KNeighborsClassifier
neighbors = np.arange(1,10)
train_accuracy =np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
for i,k in enumerate(neighbors):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
train_accuracy[i] = knn.score(X_train, y_train) #使用训练集测试准确率
test_accuracy[i] = knn.score(X_test, y_test) #使用测试集测试准确率
import matplotlib.pyplot as plt
plt.title('k-NN Varying number of neighbors')
plt.plot(neighbors, test_accuracy, label='Testing Accuracy')
plt.plot(neighbors, train_accuracy, label='Training accuracy')
plt.xlabel('Number of neighbors')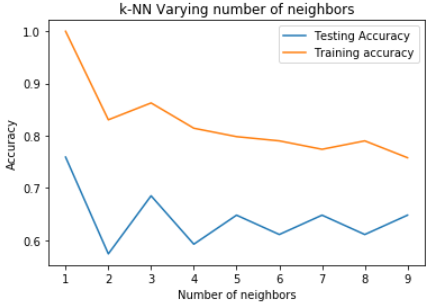
所以在本例中,K选择1是最合适的。(多次执行此代码,发现最后生成的图片不一致,原因是随机划分数据导致的)
KNN分类实战演练
数据集:diabetes
import matplotlib.pyplot as plt
df = pd.read_csv('diabetes.csv')
X = df.drop('Outcome',axis=1).values
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=42, stratify=y)
from sklearn.neighbors import KNeighborsClassifier
neighbors = np.arange(1,9)
train_accuracy =np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
for i,k in enumerate(neighbors):
#Setup a knn classifier with k neighbors
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
#Compute accuracy on the training set
train_accuracy[i] = knn.score(X_train, y_train)
#Compute accuracy on the test set
test_accuracy[i] = knn.score(X_test, y_test)
plt.title('k-NN Varying number of neighbors')
plt.plot(neighbors, test_accuracy, label='Testing Accuracy')
plt.plot(neighbors, train_accuracy, label='Training accuracy')
plt.xlabel('Number of neighbors')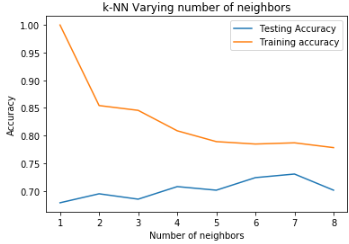
从上图中,大致确定k值取7比较合适。
参考链接: